




作者:春ying
来源:知乎
本文是对论文《Extending Halide to Improve Software Development for Imaging DSPs》关于如何拓展Halide适配DSP的解读
http://www.es.ele.tue.nl/~rjordans/downloads/vocke2017taco.pdfwww.es.ele.tue.nl
本文章主要分以下三个部分:
- DSP及其特性介绍
- Halide适配DSP的大致工作流设计
- 具体DSP优化细节
一. DSP及其特性介绍
DSP(Digital Signal Processor) 数字信号处理器,是一种具有特殊结构的微处理器。DSP芯片的程序和数据分开,具有专门的硬件乘法器,广泛采用流水线操作,提供特殊的DSP 指令,可以用来快速地实现各种数字信号处理算法。
常见的DSP有:
- Qualcomm Hexagon
- Cadence Vision DSP
- Texas EVE vision accelerator
- CEVA XM4
- Movidius Myriad M2
- Intel's DSP in Image Processing Units (IPUs)
DSP Features 特性:
- Very Long Instruction Word(VLIW)
- heterogeneous scratchpad memories
- Single Instruction Multiple Data (SIMD)
DSP的编程模型(Programming model)一般是基于C/OpenCL。
二. Halide适配DSP的大致工作流设计
Halide目前仅支持了Qualcomm Hexagon DSP。那么,拓展Halide适配其他DSP有哪些工作需要做?需要考虑哪些方面的问题?
- 后端代码生成 CodeGen
第一部分提及的DSP, 仅Qualcomm的Hexagon在LLVM有适配(llvm/Target/Hexagon),其他DSP未对接LLVM,编译用的是一般的C/C++编译器。因此若要在Halide中适配,可以考虑用Halide C code generator来适配, 生成c代码,再用DSP C Compiler进行编译。
2. 系统信息 System Description Library
需要一个模块来描述系统信息,比如:一共有多少个核(core), 每个核有多少片上内存(scratchpad memory)
3. DSP-specific Mapping Library
- SIMD指令映射
把Halide的向量加法等指令映射到目标DSP的指令,通过mapping library来实现。下图左边是Halide IR的二元操作加法的AST树,通过Halide C CodeGen可以生成普通的C代码,再通过mapping library来映射目标硬件target的SIMD指令。

- DSP相关操作的命令
可以设计新的schedule,比如 execon()来指定某些语句在DSP上执行,store_in() 显式地指定数据的存储位置等,支持remote memory的访问等。这些函数在 DSP-specific mapping library中实现
out.store_in(DSP1_MEM1)
.exec_on(DSP1);总的设计如下图所示:
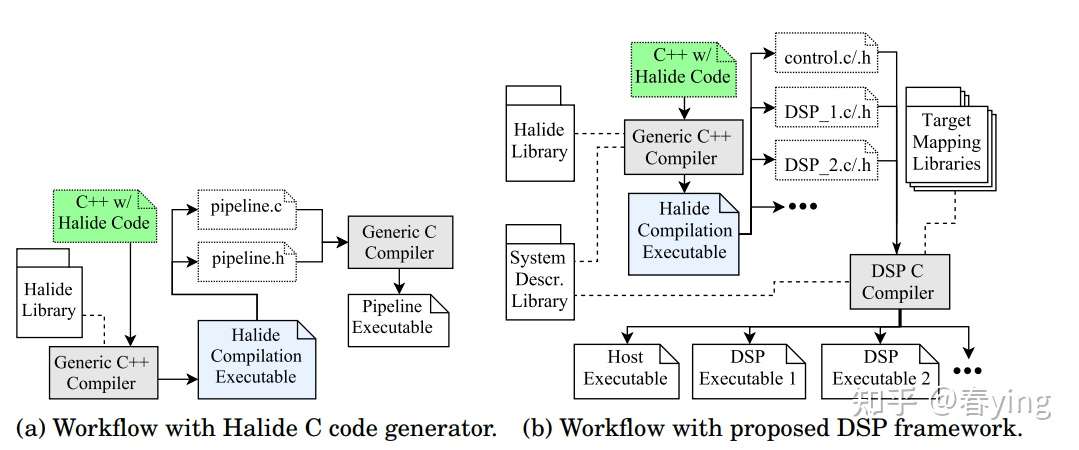
和Halide的C后端代码生成流程相比,适配DSP增加了 system description library 和 target mapping libraries, 最后生成的C代码用DSP C Compiler来进行编译。
三. DSP优化要点
3.1 便笺存储器管理 Scratchpad Memory Management
Scratchpad Memory: 也叫 Scratchpad RAM/local store, 类似L1 cache, 是除了寄存器外最接近ALU的内存,一般显示地使用指令(DMA data transfer) 来搬运数据。
设计了拓展schedule叫 store_in(), 指定某个pipeline stage来存储数据,存储在哪个内存上。下面的例子展示了cpu的buffer如何复制到DSP MEM上,在DSP上运算,并拷贝结果回cpu上。
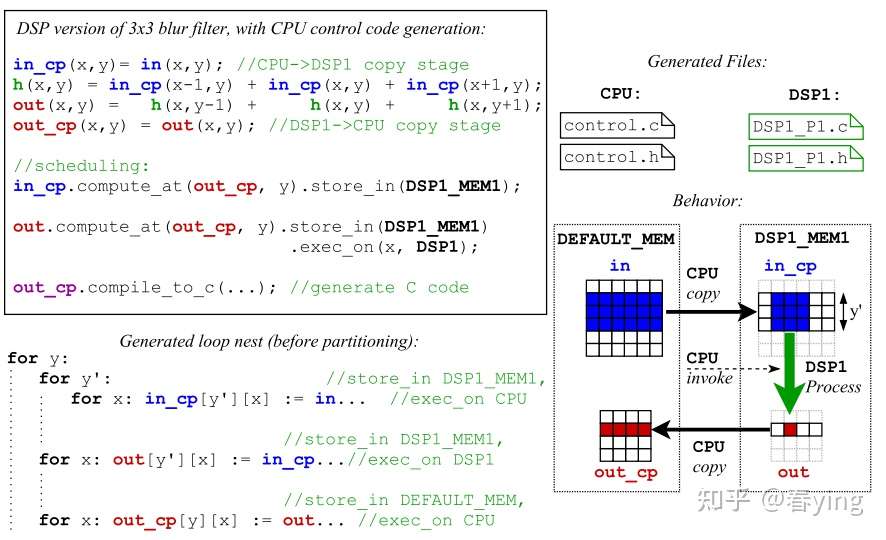
3.2 自动合并Pipeline:Automatic Pipeline Merging
目的:提高VLIW Core的并行性
DSP的并行需要考虑VLIW core, 我们希望在编译阶段可以找到尽可能多的ILP(指令级并行),那么,在源码中就体现为希望最内层循环的代码有足够的可并行的计算(尽可能少的分支,尽可能少的数据依赖),因此提出把多个循环合并成一个循环,这样这个循环体有多个输入,多个输出,彼此独立无依赖可并行。具体的实现就是合并两个pipeline, 从内层循环到外层,检测两个pipeline的共通的loop深度是否一致,若不一致,剩余的部分在loop body内。下图是合并两个pipeline P1, P2的例子:

3.4 内存访问优化
提出的关于内存优化有:
- 把重复load相同数据的减少为单个load,类似的,多次store到同个地址的,改为只store一次到该地址
- read-after-write的情况,把read改为直接用寄存器读取
- 相邻地址的多次load, 改为通过寄存器读取,添加偏移量,而不是re-load from memory, 在卷积计算中会用到这个优化
以上三点分别对应下图的 (a)(b)(c)

展望
其实,适配DSP的工作,和适配DLA, NPU,需要考虑的问题有很多是类似的,本文可作为参考。后续如果考虑做DSP/DLA/NPU的自动调优,可以基于现有的CPU/GPU自动调优框架,另外把VLIW的优化, 异构内存管理等问题考虑进来。



